[TOC]
CVPR2018
摘要
本文基于谷歌之前的RNN controller方法,是reforcement learning方法(好像也有用random search方法)。 贡献是proxy dataset:小数据集上搜索block,然后转换block到大的数据集上。 本文提出了一种新的搜索空间:NASNet search space,使这种转换成为可能(首次提出cell搜索而不是整体CNN搜索)。 本文还提出了ScheduledDropPath的正则化技术,它显著地改善了NASNet模型中的generalization(防止过拟合?。
1. Introduction
- 本文基于NAS with reinforcement learning,使用强化学习搜索神经网络架构。
- 因为在大数据集上搜索的代价很大,所以本文提出了首先在小数据集(Proxy dataset,例如CIFAR-10)上搜索,然后将搜索到的cell转移到目标数据集上(如ImageNet)。
- 本文提出的搜索空间被命名为NASNet(the NASNet search space),可以根据设置,将搜索到的架构扩展到大分辨率的数据集上。
- 搜索cell然后堆叠,而不是直接搜索网络结构的好处:①搜索速度更快;②cell更具有泛化性。通过灵活地堆叠学习到的cell,本文比较了相同计算需求下的人工网络和NAS网络的精确度差别。
- 本文也展示了在ImageNet上搜索的特征转移到别的计算机视觉任务上也是有泛化性的。本文将在ImageNet上的分类器NASNet学习到的特征和Faster-RCNN结构结合,在COCO对象识别任务上使用,获得了非常好的结果。
3. Method
本文使用的搜索方法就是NAS架构的controller RNN
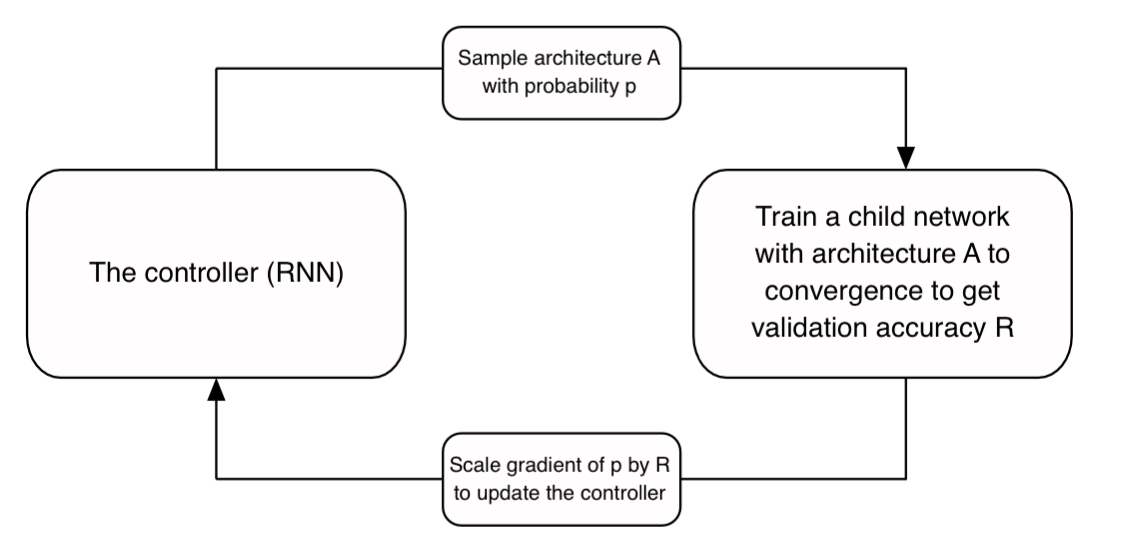
本文的inspiration来自之前的神经网络都会设计重复的CNN序列。
本文的架构是人工提前设计的。如下图所示:
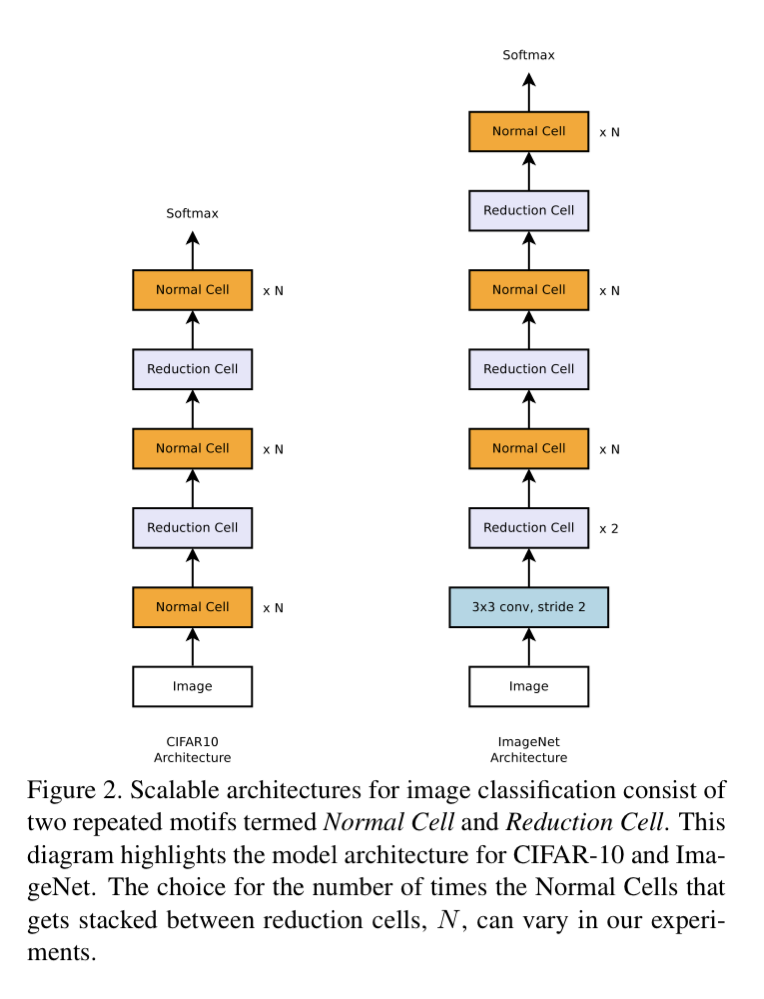 为了使整个结构具有可扩展性,需要两种结构的cell:
为了使整个结构具有可扩展性,需要两种结构的cell:
- Normal Cell:输入输出大小相同
- Reduction:输出比输入的h和w减小一半,但是输出中的dimension增加一倍,保持隐藏状态维度大致不变(in order to maintain roughly constant hidden state dimension)。
NASNet Search Space的图解: 网络模板(motifs)使用RNN迭代构建,RNN的每个迭代中:
- 选择可能的两个hidden states(灰色底色)作为输入
- 然后选择operation(黄色底色)
- 选择combination operation(绿色)
- 将结果将加入hidden states中被接下来的block作为输入选择。

controller RNN如下图所示: 一个cell中的block需要预测5个离散量(输入×2,operation×2,combination operation),每个预测输出到softmax layer中得到选择结果。
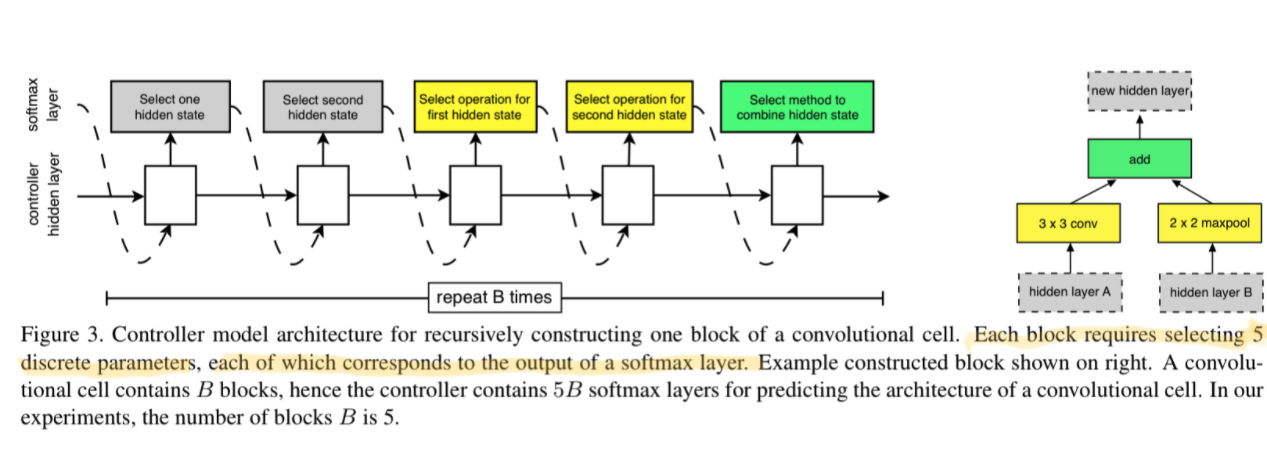
网络模板cell需要B个block,RNN就需要B×5个block。在本文中B=5
在选择operation的时候,本文设定了以下的operation layer供选择:

在选择combination operation的时候,本文设定两种方法:(1)element-wise addition;(2)concatenation
在cell的结尾,所有没有被输入到某个block中的hidden states会被concat输出。
为了同时预测Normal cell和Reduction cell,本文简单地将RNN扩展到2×5B个block,前5B预测Normal,后5B预测Reduction。
如果要使用random search代替reforcement search:用于得到预测结果的从RNN block尾部的softmax layer换成从分布中随机采样得到。
4.experiments and results
使用PPO(proximal policy optimization Algorithm)进行训练
在训练NASNets的时候,提出了一个有效的regularization方法,ScheduledDropPath。是DropPath的改进。
- DropPath:在训练时,根据固定参数,随机drop掉cell中的path
- ScheduledDropPath:根据随着训练过程线性增加的参数来drop path。
在CIFAR-10上训练,使用500 V100 GPU训练了4天。CIFAR-10上获得了超过同期最好的效果。 在ImageNet上训练,使用不同的N和block内filter数,和同期进行对比,state-of-art同时FLOPS和MAC少。 在COCO detection上,将cell插入Faster-RCNN。