[TOC]
CVPR2020
说实话,这篇paper是我这几天看的最狗屁不通的一篇,不是说idea不好,是他妈简单能够讲清楚的结构你踏马嵌套了多少自创名词谁他妈看得懂
Abstract
感觉像是reinforcement方法
本文提出的方法针对密集图像识别任务。
本文使用一系列的 auxiliary cell将结构过参数化(over-parameterise),auxiliary cell在训练中会提供中间监督信号。
auxiliary cell是通过一个controller使用reinforcement learning获得的。
本文还使用了渐进式的策略(progressively strategy)将没有前途的结构在训练中途终止,然后使用Polyak averaging和knowledge distillation来加速收敛。
本文在8GPU上训练,在semantic segmentation、pose estimation、depth prediction task上都进行了验证。源码公开在github resposity
1. Introduction
本文的目标:
-
high-performance 密集图像任务的模型
-
可以在low-computing platfrom上使用
考虑一个Encoder-decoder结构,其中的encoder是一个预训练好的图像分类器,decoder则由controller得到。
controller控制生成encoder和decoder之间的连接结构,以及每个链接路径上的operation序列(即形成了cell)。
使用相同的cell结构形成的辅助分类器(Auxiliary classifier)将会提供中间监督和隐式的超参数模型。辅助分类器在训练时使用,inference时被丢弃。
本文贡献:
-
提出了渐进式训练策略,保证了没有前途的候选模型在训练前期就被放弃
-
提出使用knowledge distillation和Polyak averaging的方法的训练策略
-
使用了超参数化的auxiliary cell
3. 方法
3.1 搜索空间
搜索空间整体如下图所示,使用了传统的encoder-decoder结构,其中encoder模型使用的是pretrained MobileNet-v2,而decoder模型则使用controller生成。

encoder有四个层的不同分辨率的输出,输入到1x1conv中保证通道数相同。
然后,controller控制两个部分的结构,一个是block的输入输出,一个是cell内部的结构:
- block的输入输出:
一个block包含两个输入、两个cell对输入操作、最后结果concat并且输出。
第一个block的输入来自四个encoder layer output中选择两个,可以相同也可以不同。
(如上图controller负责输出的block4)
然后经过相同结构、不同weight的cell之后,结果进行concat,并且加入候选candidate set,继续下一个block的选择(这个把结果加入candidate set的操作在本文中被包装成replacement这个词,不明所以)
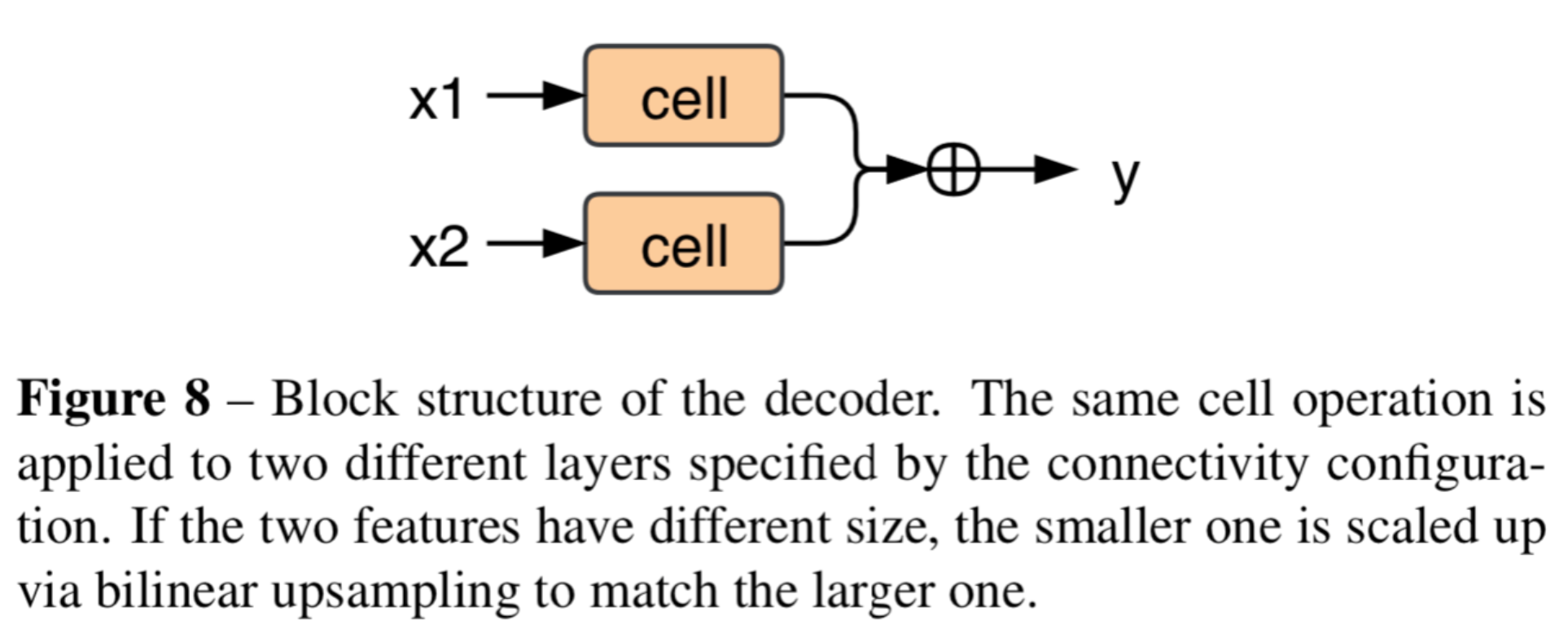
在本文中,block被设置为三。
所有没有被使用的candidate set的feature map将会concat然后使用1x1卷积来整合通道数,并最后输入到classification layer中。
- cell内部结构:
如上面整体图的sample cell structure所示。
一开始candidate set只有cell的输入一个,然后使用RNN选择对其进行的op,结果加入到candidate set中。
然后接下来的每轮,在candidate set中选择2个输入和op,结果concat,加入candidate set。(这里也是replacement,完全不明所以)

这张图的黑线是实际上选择的route,虚线是可以选择的route。
在本文中这样的选择进行3次。
所有可能的op:

3.2 搜索策略
reforcement learning有两个的优化:外部的优化对controller进行,内部的优化对controller得到的网络architecture进行。本文使用PPO优化外部controller,针对的是内部的优化阐述策略
3.2.1 progressive Stages
将网络结构优化分为两个stage,在第一个stage中,encoder的weight被固定,因此它的输出是固定的,不需要计算,只需要拿着它的输出去优化decoder就可以。
使用启发式的方法来决定是否进行第二个stage的训练:如果结果低于平均的rewards,那么有1-p的可能性停止训练。p在最开始设置为0.9,逐渐降低。
这一设置的想法很简单:早期训练的结果可以显露出这一结构的潜力。
3.2.2 使用了knowledge distill和weights’ averaging的fast training
没仔细写 也看不懂
3.2.3 使用了Auxiliary Cell的中间监督
4. 实验
太励志了,整个实验在两个1080Ti上进行的,搜索进行了4天。
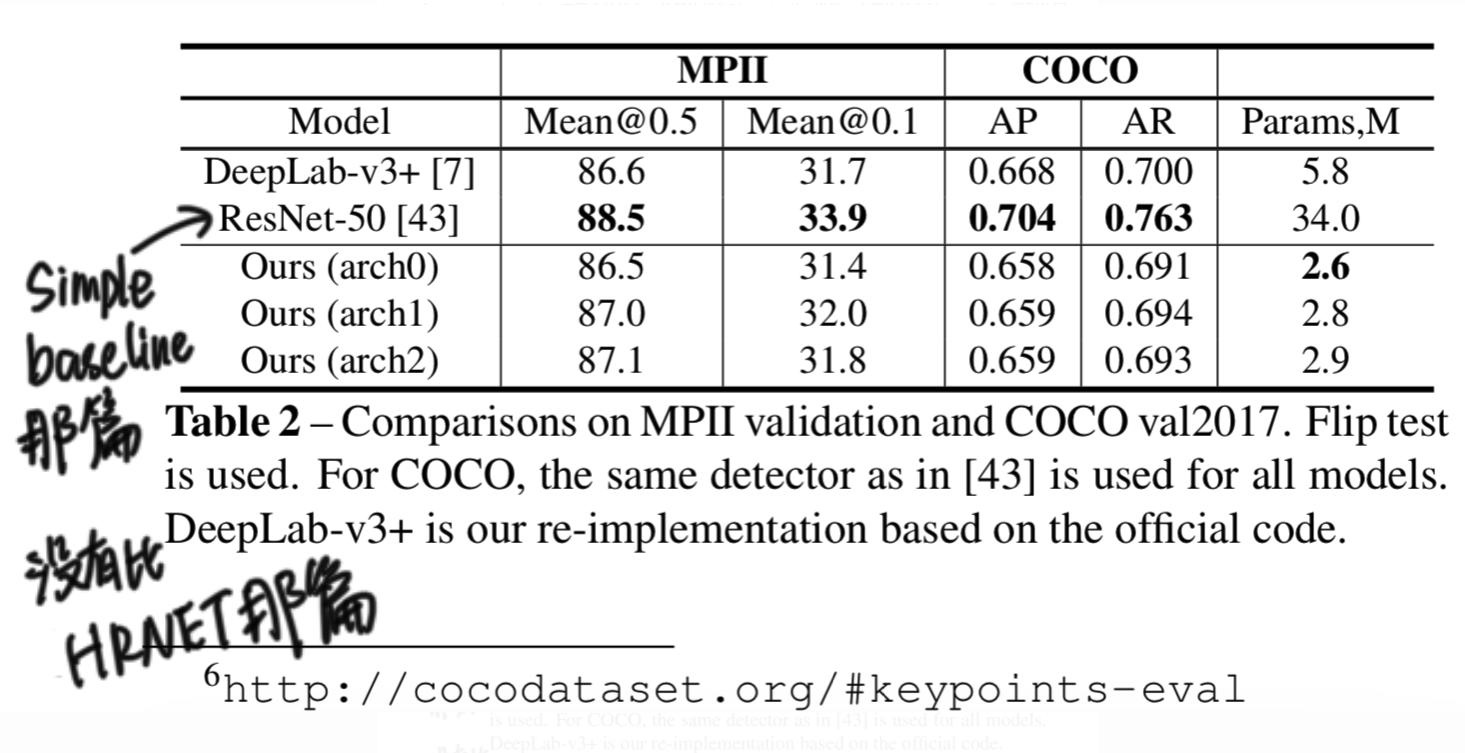
pose estimation的transfer learning
follow了simple baseline那篇的搜索设置。